This post is motivated by my recent read of Invariant Risk Minimization (IRM) by Arjovsky et al. (2019). When it comes to the identically and independently distributed (iid) assumption in its concluding dialogue, the image (e.g., MNIST) classification example triggered an interesting discussion on the relationship between causal/anticausal learning and supervised/unsupervised learning. Simply put, the dispute lies in the core question of whether or not image classification is a causal problem. In the dialogue, the authors delivered us two mutually exclusive opinions: causal versus anticausal. Although both make sense to some extent, there might exist another more generally reasonable viewpoint. In this post, I will first briefly summarise the two opinions discussed in the paper, with a further analysis, and then explore another in more details.
Note that, for a straightforward comparison, I accordingly modified the figure presented in the paper for each opinion.

Figure 1: Image classification is an anticausal problem.
Opinion 1: Image classification is an anticausal problem.
Professor Schölkopf once explained that MNIST classification is an anticausal problem, i.e., predicting cause from effect, where the observed digit image is viewed as an effect of its label which is encoded as an high level concept of interest in human brain (Schölkopf et al., 2012). In this case, the process of generating an digit image can be described as follows: the writer first has a high level concept of interest in his mind (i.e., which digit to draw?), and then writes the digit through a complex sequence of biochemical reactions and sensorimotor movements. As such, when trying to predict its label from an image, we are actually inverting the generating process, with the aim to predict cause (label) from effect (image), as shown in Figure 1.
A supporting evidence is that in semi-supervised learning an additional set of images usually contribute to the improvement of classification performance. Technically, given training points from 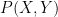
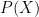


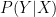

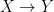
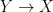
I encourage readers who are interested in the discussion on semi-supervised learning and causality to follow up with the initial work by Schölkopf et al. (2012).
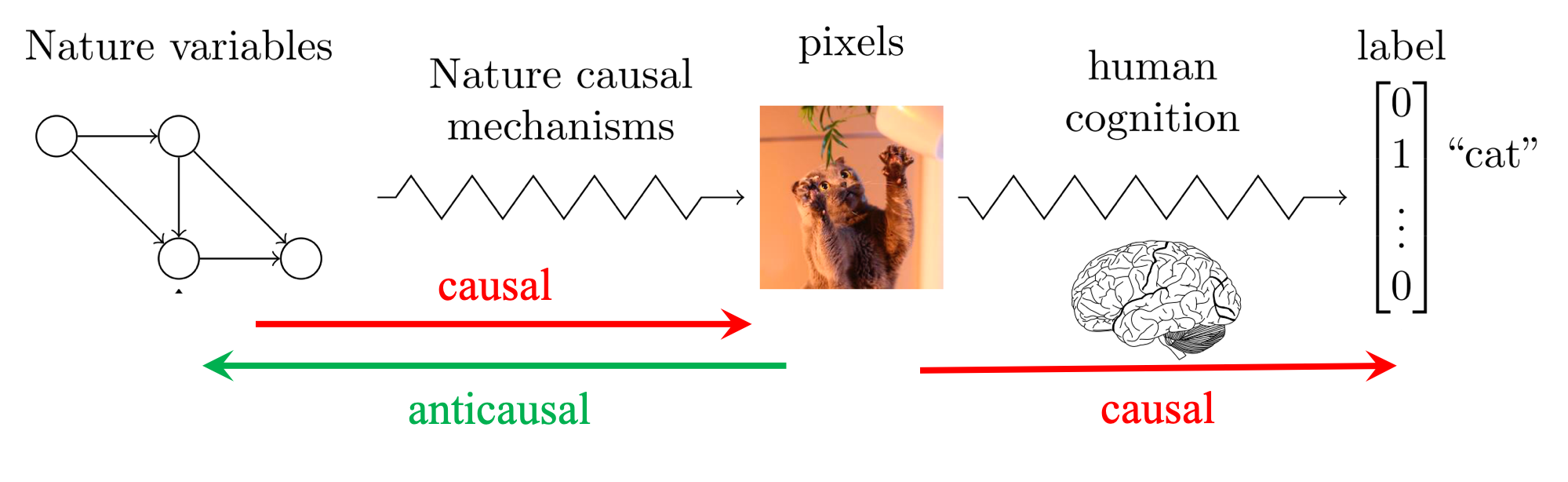
Figure 2: Image classification is a causal problem.
Opinion 2: Image classification is a causal problem.
Professor Eric, who is a fictional character in the IRM paper and who is promoted by me from Graduate Student to Professor to convince readers more, has a different viewpoint from Professor Schölkopf. He claimed that image classification is a causal problem, which attempts to predict human annotations
On the LHS of Figure 2, we can interpret the process from two directions. In the causal direction, Nature variables (e.g., colour, light, angle, animal, etc.) produce images through nature causal mechanisms. In the anticausal direction, we attempt to disentangle the underlying causal factors of variation behind images (i.e., Nature variables), a.k.a. unsupervised learning. In the anticausal process, “inference” might be a more accurate term than “disentanglement”, because Nature variables are unnecessarily independent. In fact, one knows neither what true Nature variables are nor what true relations between them are. Instead, one only knows Nature variables on a certain level, depending on how much prior knowledge one has of the problem to be addressed. This will result in multiple levels of “Nature variables”, ranging from fine to coarse, and further lead to multiple levels of causal graphs made of “Nature variables”. For instance, a set of closely connected fine “Nature variables” in a fine causal graph might become one coarse “Nature variable” in its corresponding coarse causal graph. Actually, in most scenarios we do not need to know the true causal graph. It is often enough to infer the causal graph on our understanding level. The simplest explanation is best (Occam’s Razor).

Figure 3: The Agnostic Hypothesis.
The Agnostic Hypothesis: Image classification is not only a causal problem but an anticausal problem as well.
As an agnostic, I prefer to look at the image classification problem from the agnostic viewpoint (i.e., absence of evidence is not evidence of absence). Precisely, I would like to believe in the Agnostic Hypothesis that there must be a third party of hidden variables (Nature variables) (
Theory of Forms. Plato’s Theory of Forms (Edelstein, 1966) asserts that there are two realms: the physical realm, which is a changing and imperfect world we see and interact with on a daily basis, and the realm of Forms, which exists beyond the physical realm and which is stable and perfect. This theory asserts that the physical realm is only a projection of the realm of Forms. Plato further claimed that each being has five things: the name, the definition, the image, the knowledge, and the Form, the first four of which can be viewed as the projections of the fifth. In this sense, the Agnostic Hypothesis is explicitly consistent with Plato’s theory.
Manipulability Theory. It provides a paradigmatic assertion in causal relationships that manipulation of a cause will result in the manipulation of an effect. In other words, causation implies that by varying one factor I can make another vary (Cook & Campbell 1979). Based on this theory, it makes sense that image causes label, because changes in image will apparently lead to changes in label. Nevertheless, the converse that label causes image is also reasonable in that changes in label will definitely result in changes in images. Since it is clear that there is no causal loop, be it temporal or not, between images and labels, there must be something hidden behind. Hence, the theory indirectly supports the claim above.
Principle of Common Cause. The relation between association and causation was formalized by Reichenbach (1991): If two random variables
Now let us investigate whether or not the agnostic hypothesis can give a better explanation.
Firstly, we can think of image and label as two different representation spaces projected from Nature variables via Nature causal mechanism and Human cognitive mechanism, respectively. In other words, image is the way Nature interprets Nature variables whilst label is the way Human interprets them. Hence, both are the effects of Nature variables, but on different levels (i.e., label is more abstract than image).
Secondly, in light of the fork junction (i.e., 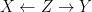
Thirdly, almost all the existing approaches to image classification consist of two parts: a feature extractor and a classifier, whether explicitly or implicitly. For example, traditional approaches are usually explicitly made up of a handcrafted feature extractor and a well-chosen classifier. By contrast, deep learning approaches appear more implicit, where deep neural networks can be always split into two components, the first of which can be viewed as a feature extractor and the second as a classifier. In effect, this setting can be well explained by the blue arrow in Figure 3 that is composed of an anticausal process from image to Nature variables and a causal process from Nature variables to label. We can think of the anticausal part as a feature extractor and the causal part as a classifier. Ideally, if we have a perfect feature extractor, then we can infer the true Nature variables from images. Under this circumstance, the learned classifier based on true Nature variables should be invariant across environments, because true Nature variables are causal parents of labels, as discussed in both IRM and ICP (Peters et al., 2016). In practice, however, it is difficult even to obtain a suboptimal feature extractor being able to infer coarse “Nature variables”, let alone the perfect one. Hence, most existing approaches focus on how to approximate it in some sense.
Apparently, all the explanations above are not limited to image classification and also apply to many other supervised learning problems. Besides, a large number of machine learning topics can be placed and explained under the agnostic hypothesis framework, e.g., autoencoders, adversarial attacks, information bottleneck, to name a few. Take adversarial attacks (Goodfellow et al., 2015) for example. The reason why it is far too easy to fool ConvNets with an imperceivable but carefully constructed noise in the input is that the feature extractor part of ConvNets did not correctly infer the true Nature variables in the anticausal direction. Hence, the learned predictive link between image and label is so unstable that a small disturbance on the input image will lead to wrong Nature variables misguiding the classifier part. As discussed aforementioned, learning an optimal or near-optimal feature extractor could address or mitigate this issue.
Talk: The Agnostic Hypothesis: Machine Learning’s Achilles Heel or Midas Touch?
Citation
For attribution in academic contexts or books, please cite this work as
Chaochao Lu, “Is Image Classification a Causal Problem?”, Blogpost at causallu.com, 2020.
BibTeX citation:
@article{lu2020imageclassification,
author = {Lu, Chaochao},
title = {Is Image Classification a Causal Problem?},
journal = {Blogpost at causallu.com},
year = {2020},
howpublished = {\url{https://causallu.com/2020/04/05/is-image-classification-a-causal-problem/}},
}

Could you please leave the citations of this article?
LikeLike
You can find all or even more of these references in section 7 of our paper: Nonlinear Invariant Risk Minimization: A Causal Approach (https://arxiv.org/abs/2102.12353). Hopefully this will help you.
LikeLike
Thanks a lot!
LikeLike
Like your blog and your ideas! The causal and anticausal problem question becomes a philosophical question, “nominalism or realism?”.
LikeLike