1. Introduction
In the past decade, machine learning has been playing an increasingly important role in the revolution of artificial intelligence (AI). As the products and services driven by machine learning technology are becoming widespread in our daily life, in particular in those life-critical applications (e.g., self-driving, medicine, healthcare, etc.), the demand for artificial intelligence properties (AIP), such as safety, robustness, and interpretability, has appeared unignorable in machine learning. The reason why we call these properties AIP is that they are indispensable to AI, each reflecting one vital aspect of AI. Without such a guarantee on AIP, all the results yielded by machine learning systems would be unstable, uninterpretable, and untrustworthy, which will put human life and economy at great risk.
Although many efforts have been devoted to meeting the demand for AIP, the current machine learning theories still have a long road to make it. In fact, in machine learning community researchers have not yet reached a consensus on the matter of what plays a fundamental role in satisfying the requirements of AIP. Under this circumstance, it is pressing to rethink the perspective from which we look at machine learning.
It is widely acknowledged that the focus of machine learning is on prediction and that at the core of prediction is generalisation. It is further argued that it is invariance that plays a pivotal role at the heart of generalisation [Peters et al., 2016, Peters et al., 2017, Bühlmann, 2018, Vapnik, 2019]. Also, it is, without doubt, that causality is one of the best tools to investigate invariance [Peters et al., 2017]. All these are summarised in Figure 1. For this reason, in this study, we naturally attempt to rethink machine learning through the causal lens.

In my previous blogpost, we analysed two existing mutually exclusive opinions (i.e., causal versus anticausal) on supervised learning through a motivating example of image classification, and showed that both views are unable to provide a promising way to satisfy AIP. As such, there we proposed a more general view, namely the Agnostic Hypothesis, that there exist a third party of Nature Variables (i.e., elemental hidden variables) affecting both the input and the output of supervised learning. We argue that Nature Variables are the key to meeting the requirements of AIP. We further find that the Agnostic Hypothesis can provide a unifying view of machine learning, whether supervised, unsupervised or reinforcement learning. More importantly, since under the Agnostic Hypothesis data are viewed as projections or views of Nature Variables, we are inspired to propose a conjecture, called Multiview Universal Approximation (MUA), which is based on the intuition that the more diverse views of Nature Variables we have, the more accurate estimate of Nature Variables we can attain. In this sense, we can leverage MUA to help identify Nature Variables from data both theoretically and practically. For this reason, we further argue that MUA is a solution to satisfying AIP in machine learning. From the point of view of MUA, we show that the unifying view based on the Agnostic Hypothesis can help identify the issues (e.g., poor generalisation, instability, uninterpretability, etc.) in current machine learning algorithms, understand why algorithms work, inspire new algorithm designs, and eventually inspire a new machine learning theory.
Here we conceptually explain why it universally makes sense that Nature Variables are the key to satisfying AIP. Without loss of generality, we continue taking image classification for example. Ideally, if we have a perfect feature extractor, then we can infer Nature Variables from images, which will, to the largest extent, reduce the negative influence from irrelevant noisy information on the input. In other words, the perfect feature extractor can defeat the attack on the input so as to guarantee safety and robustness of the systems in terms of the input information. Furthermore, because Nature Variables are causal parents of labels, the learned classifier based on Nature Variables should be invariant across environments or domains as discussed in [Arjovsky et al., 2019, Peters et al., 2016], which guarantees safety and robustness of the systems in terms of the output information. More importantly, once Nature Variables are obtained, we would know how they influence one another and how they affect both images and labels. It would thus render the systems’ behaviours more interpretable.
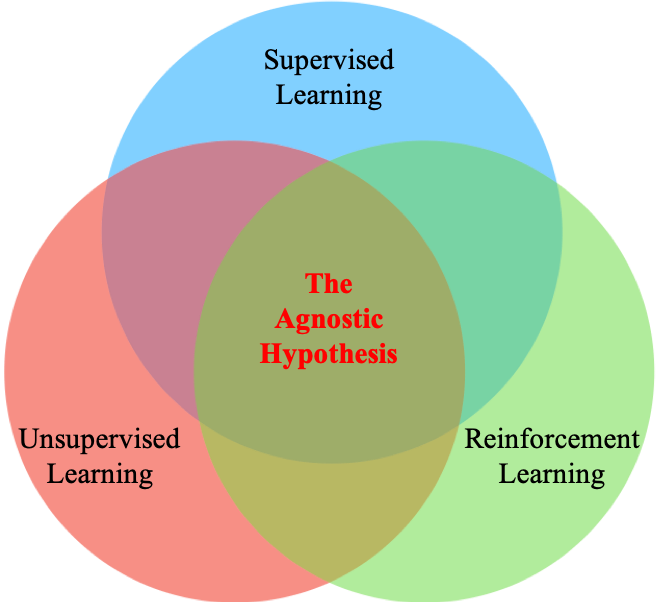
2. A Unifying View of Machine Learning
All the explanations above are not limited to image classification and also apply to general machine learning problems. In fact, the Agnostic Hypothesis provides a unifying view of machine learning as shown in Figure 2, which paves the way for inspiring both new algorithm designs and a new theory of machine learning. In this section, we first re-interpret machine learning, which are widely categorised as supervised, unsupervised, or reinforcement learning, under the Agnostic Hypothesis. Then, we discuss the implications of such a unifying view and its practical consequences, which are substantiated by the experimental results found in the literature.
2.1. Supervised Learning
When the training data contains examples of what the correct output should be for given inputs, as aforementioned, under the Agnostic Hypothesis the inputs and the correct outputs can be thought of as two different representation spaces projected from Nature Variables via two different mechanisms. In other words, inputs and outputs are two distinct interpretations or views of Nature Variables.
2.2. Unsupervised Learning
When the training data just contains inputs without any output information, there are several scenarios. If the input data come only from one domain, under the Agnostic Hypothesis they are interpreted as just one projection or view of Nature Variables. If they are from multiple transforms or variants of the same domain [Chen et al., 2020], they are naturally viewed as multiple projections or views of Nature Variables.
2.3. Reinforcement Learning
A reinforcement learning agent is learning what to do, i.e., how to map situations to actions, so as to maximise a numerical reward signal [Sutton and Barto, 2018]. Rather than being directly told which action to take, the agent must learn from sequences of observed information (i.e., states/observations in a fully/partially observable environment, actions, and rewards). Under the Agnostic Hypothesis, each component of the observed information reflects one aspect of the environment and can be thus viewed as one projection or view of Nature Variables. Note that, although uncovering structure in an agent’s experience itself, whose perfect representation should be undoubtedly in some form of Nature Variables, does not address the reinforcement learning problem of maximising a reward signal, it plays a vital role in real world reinforcement learning applications with strong demand for AIP [Garcia and Fernández, 2015, Gros et al., 2020].
2.4. Implications of a Unifying View
The reason why we should look at machine learning from the unifying view of the Agnostic Hypothesis is that compared to the traditional view, it offers a promising way to explore the requirements of machine learning for AIP in the real world applications. As stated in [Russell and Norvig, 2002], the representation of the learned information plays a pivotal role in determining how the learning algorithm must work. Hence, from the unifying view, all the required properties of machine learning are rooted in how accurately we can estimate Nature Variables from data, because Nature Variables are, without doubt, the optimal representation of the data.
Now the question comes to whether or not it is possible to identify Nature Variables from data. Considering that under the Agnostic Hypothesis the data in reality are viewed as projections or views of Nature Variables, one naturally has an intuition that the more diverse views of Nature Variables we have, the more accurate estimate of Nature Variables we can attain. For convenience, we call this intuition Multiview Universal Approximation (MUA). Not surprisingly, some theoretical works have demonstrated MUA to some extent by showing that under some assumptions multiple views will lead to identifiability of Nature Variables up to some affine ambiguity [Gresele et al., 2019]. Actually, under some stronger assumptions only two views are even capable of identifying Nature Variables up to some unavoidable indeterminacy [Hyvarinen et al., 2019, Gresele et al., 2019]. Although these initial works are predicated on strict assumptions on Nature Variables (e.g., Nature Variables are assumed to be independent or conditionally independent of each other, which, as aforementioned, is unnecessary in reality, etc.), they are a good starting point on the road towards the general theory of MUA.
From this point of view, the unifying view based on the Agnostic Hypothesis has at least four practical implications.
a) It can help identify the issues in current machine learning algorithms. For example, in the research of adversarial attacks [Goodfellow et al., 2015], the reason why it is far too easy to fool convolutional networks with an imperceivable but carefully constructed noise in the input is that the feature extractor part of the networks cannot accurately infer the Nature Variables in the anticausal direction. Hence, the learned predictive link between image and label is so unstable that a small disturbance on the input image will lead to wrong Nature Variables misguiding the classifier part. This issue widely exists in supervised learning, because at the testing time only one view is used to infer Nature Variables. This issue could be mitigated if the input data involve multiple views in some scenarios, such as in time series prediction problems that take as input multiple time step data and each time step can be viewed as one view of Nature Variables.
b) It can help understand why algorithms work. For instance, it is reasonable that multitask learning [Caruana, 1997] has been used successfully across all applications of machine learning, because multitask data provide multiple views of their shared features (Nature Variables), making inferring them more accurate as suggested in MUA. Another example is that in reinforcement learning, one widely leveraged multiview data to discover the invariant part of states [Lu et al., 2018, Zhang et al., 2020].
c) It can help inspire a new algorithm design. It is worth noting that an unsupervised learning approach, proposed in a very recent work [Chen et al., 2020], leverages data augmentation to considerably outperform previous methods for self-supervised and semi-supervised learning and even to be on a par with supervised learning methods on ImageNet. It indeed makes sense, because data augmentation created multiple views of latent features (Nature Variables), leading to identifying Nature Variables more accurately as stated in MUA.
d) It can help inspire a new theory of machine learning. As mentioned previously, current machine learning theories neither satisfy the demands for AIP in real world applications nor answer the key question of how to discover Nature Variables from data [Vapnik, 2019]. The unifying view provides a promising way to address both issues by developing a general theory of MUA with more relaxed assumptions, because under the Agnostic Hypothesis MUA is a natural and feasible way to identify Nature Variables as mentioned previously. Another possible thread of discovering them is through intervention [Pearl, 2009] if it is allowed to interact with environments.
3. Discussion
The Agnostic Hypothesis can be viewed as a kind of description of the relationship between invariants and variants, where invariants are reflected by Nature Variables and variants by their corresponding projections or views. In this sense, the Agnostic Hypothesis has a long history in philosophy and science. It can be dated back to the time of Plato, whose Theory of Forms described the relationship as aforementioned. Inheriting from Plato, Hegel argued that there exists a higher level of cognition commonly taken as capable of having purportedly eternal contents (i.e., invariants) which come from the changing contents (i.e., variants) based in everyday perceptual experience. Furthermore, Wigner summarised physics as a process of discovering the laws of inanimate nature, that is, recognising invariance from the world of baffling complexity around us [Wigner, 1990]. Recently, Vapnik was motivated to propose a complete statistical theory of learning based on statistical invariants constructed using training data and given predicates [Vapnik, 2019]. Roughly speaking, a predicate is a function revealing some invariant property of the world of interest, like the Form in Plato’s theory.
Although in philosophy many agreed on that there exist such invariants beyond the variants, they did not reach a consensus on whether or not they are apprehensible. For example, Kant thought that there is some unknowable invariant, called thing-in-itself, outside of all possible human experience [Kant, 1998]. However, Schopenhauer believed that the supreme invariant principle of the universe is likewise apprehensible through introspection, and that we can understand the world as various manifestations of this general principle [Schopenhauer, 2012]. Despite the controversy in philosophy, Vapnik still provided two examples in art to show that it might be possible to comprehend those invariants to some extent [Vapnik, 2020]. One is that Bach’s music is full of repeated patterns. The other is that Vladimir Propp, a Soviet formalist scholar, analyzed the basic plot components of Russian folk tales to identify 31 simplest irreducible narrative elements which are so general that they also apply to many other stories and movies. Both seemingly demonstrate that there exist such invariants at least in some form. It is thus natural to ask how we can identify them from data, which is so important that Vapnik thought that the essence of intelligence is the discovery of good predicates [Vapnik, 2020]. Schmidhuber once expressed a similar opinion that “all the history of science is the history of compression progress”, where obviously the optimal compression should be in the form of Nature Variables [Schmidhuber, 2018]. Bengio also proposed a consciousness prior for learning representations of high-level concepts [Bengio, 2017]. As such, we hope that the Agnostic Hypothesis can provide a new direction to explore the general theory of MUA for identifying Nature Variables both theoretically and practically, which is key to satisfying the demand for AIP in machine learning.
Acknowledgements
I would like to thank Bernhard Schölkopf and Hannes Harbrecht for useful discussions and feedback.
Citation
For attribution in academic contexts or books, please cite this work as
Chaochao Lu, “The Agnostic Hypothesis: A Unifying View of Machine Learning”, Blogpost at causallu.com, 2020.
BibTeX citation:
@article{lu2020unifyingview,
author = {Lu, Chaochao},
title = {The Agnostic Hypothesis: A Unifying View of Machine Learning},
journal = {Blogpost at causallu.com},
year = {2020},
howpublished = {\url{https://causallu.com/2020/10/24/the-agnostic-hypothesis-a-unifying-view-of-machine-learning/}},
}
References
[Agamben, 1999] Agamben, G. (1999).Potentialities: Collected essays inphilosophy. Stanford University Press.
[Arjovsky et al., 2019] Arjovsky, M., Bottou, L., Gulrajani, I., andLopez-Paz, D. (2019).Invariant risk minimization. arXiv preprintarXiv:1907.02893.
[Bengio, 2017] Bengio, Y. (2017). The consciousness prior.arXiv preprintarXiv:1709.08568.
[Bühlmann, 2018] Bühlmann, P. (2018). Invariance, causality and robust-ness.arXiv preprint arXiv:1812.08233.
[Caruana, 1997] Caruana, R. (1997). Multitask learning.Machine learning,28(1):41?75.
[Chen et al., 2020] Chen, T., Kornblith, S., Norouzi, M., and Hinton, G.(2020). A simple framework for contrastive learning of visual representations.arXiv preprint arXiv:2002.05709.
[Cook and Campbell, 1979] Cook, T. and Campbell, D. (1979). Experimental and quasi-experimental designs for research.Chicago und IL: RandMcNally.
[Edelstein, 1966] Edelstein, L. (1966).Plato?s seventh letter, volume 14.Brill.
[Garcia and Fernández, 2015] Garcia, J. and Fernández, F. (2015). A comprehensive survey on safe reinforcement learning.Journal of MachineLearning Research, 16(1):1437?1480.
[Goodfellow et al., 2015] Goodfellow, I. J., Shlens, J., and Szegedy, C.(2015). Explaining and harnessing adversarial examples.InternationalConference on Learning Representations.
[Gresele et al., 2019] Gresele, L., Rubenstein, P., Mehrjou, A., Locatello,F., and Schölkopf, B. (2019). The incomplete rosetta stone problem:Identifiability results for multi-view nonlinear ica. In35th Conference onUncertainty in Artificial Intelligence (UAI 2019), pages 296?313. Curran.
[Gros et al., 2020] Gros, S., Zanon, M., and Bemporad, A. (2020). Safereinforcement learning via projection on a safe set: How to achieve optimality?IFAC.
[Hyvarinen et al., 2019] Hyvarinen, A., Sasaki, H., and Turner, R. (2019).Nonlinear ica using auxiliary variables and generalized contrastive learning. InThe 22nd International Conference on Artificial Intelligence andStatistics, pages 859?868.
[Kant, 1998] Kant, I. (1998).Critique of Pure Reason. Cambridge University Press.
[LeCun et al., 1998] LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P.(1998). Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278?2324.
[Lu et al., 2018] Lu, C., Schölkopf, B., and HernándezLobato, J. M. (2018).Deconfounding reinforcement learning in observational settings. arXivpreprint arXiv:1812.10576.
[Pearl, 2009] Pearl, J. (2009).Causality. Cambridge university press.
[Peters et al., 2016] Peters, J., Bühlmann, P., and Meinshausen, N. (2016).Causal inference by using invariant prediction: identification and confidence intervals.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 78(5):947?1012.
[Peters et al., 2017] Peters, J., Janzing, D., and Schölkopf, B. (2017).Elements of causal inference. The MIT Press.
[Reichenbach, 1991] Reichenbach, H. (1991).The direction of time, volume 65. Univ of California Press.
[Russell and Norvig, 2002] Russell, S. and Norvig, P. (2002).Artificial intelligence: a modern approach.
[Schmidhuber, 2018] Schmidhuber, J. (2018).Godel machines, meta-learning, and lstms. https://youtu.be/3FIo6evmweo.
[Schölkopf et al., 2012] Schölkopf, B., Janzing, D., Peters, J., Sgouritsa, E.,Zhang, K., and Mooij, J. (2012). On causal and anticausal learning.International Conference on Machine Learning, pages 459?466.
[Schopenhauer, 2012] Schopenhauer, A. (2012).The world as will and representation, volume 1. Courier Corporation.
[Sutton and Barto, 2018] Sutton, R. S. and Barto, A. G. (2018).Reinforcement learning: An introduction. MIT press.
[Vapnik, 1992] Vapnik, V. (1992). Principles of risk minimization for learn-ing theory. InAdvances in neural information processing systems, pages831?838.
[Vapnik, 2020] Vapnik, V. (2020). Predicates, invariants, and the essence of intelligence. https://youtu.be/bQa7hpUpMzM.
[Vapnik, 2019] Vapnik, V. N. (2019). Complete statistical theory of learning.Automation and Remote Control, 80(11):1949?1975.
[Wigner, 1990] Wigner, E. P. (1990). The unreasonable effectiveness of mathematics in the natural sciences. In Mathematics and Science, pages291?306. World Scientific.
[Wittgenstein, 2009] Wittgenstein, L. (2009). Philosophical investigations. John Wiley & Sons.
[Zhang et al., 2020] Zhang, A., Lyle, C., Sodhani, S., Filos, A.,Kwiatkowska, M., Pineau, J., Gal, Y., and Precup, D. (2020). Invariant causal prediction for block mdps. arXiv preprint arXiv:2003.06016.
